Windows port
Windows port of Open ZFS
What I did during my summer vacation.
The ZOW (nice acronym!) port does not yet have its own home, but I wanted to jot down some things I have come across while doing the port. There will be a mixture of information for myself, the occasional difference to Unix that surprised me and other left-side experiences. Since my background and knowledge comes from Unix, it is mostly looking at the way that Windows does things, so it is unlikely a Windows developer would say anything but "Of course it does it this way!". Still, it has been an interesting journey. This journey is of my naive "young" self (past lundman was younger!), making assumptions that was just wrong and my "a-ha!" moment that followed.
I actually had a good time challenging myself with this, so I've tried my utmost to make this text be void of bitterness, as the stereotype would demand :)
The first brick wall I hit was actually in the very first couple of weeks. Yes, there is a "Hello World" kernel (Windows Driver) example which I tried to compile to "run". This was surprisingly complex a task, a lot of information that is stale led me down the way you would do it if you were still running Windows XP. Just too much information exists. Eventually I figured out that "current" best way is to deploy with VisualStudio to a remote VM, where VS will copy the compiled binary over and "load" it into the running kernel. When I created the first project file, I called it "Open ZFS on Windows". Each time I had to re-create the project in frustration (as nothing worked, not even rebooting! So much rebooting) I deleted one of the characters. In the end, it was "ZFSin" that finally had some progress. I feel I got close to giving up then, before I even started.
At first, the porting consisted of changing over the SPL primitives, like atomics, mutex, condvars, rwlocks, threads and taskqs, and all that. It is pretty straight forward porting work, and you never know if it'll work at this point, or be worth it.
Since OsX already runs with Solaris/IllumOS's memory manager, kmem, it was easy to compile that for Windows as well. It is a page allocator with slab support and magazines, kmem_caches etc. Done by Jeff Bonwick many moons ago. So we are already familiar with it, and it has great debugging features to find memory corruption, modify-after-free and so on. So kmem now runs on Windows, Jeff will just have to find some way to live with that. :)
The first real porting of a function, was the Unix panic() call. Ie, things have gone so bad, we want to purposely terminate the kernel. Used by the VERIFY macros throughout the ZFS sources.
During my first ZFS porting work, to OsX, the biggest annoyance when Googling for information was the lack of said information. There just is not many kernel devs on OsX, especially in the filesystem genre.
With Windows, I quickly found the opposite to be true. When trying to Google for how to trigger a BSOD (Blue screen of death), the first 1,000 or so hits are about "Troubleshooting: How to fix your BSOD!". As a side note here Windows people, when the steps to troubleshoot, includes "try re-installing Windows". That is not troubleshooting, that is giving up.
Anyway, the next lot of "thousand hits" are "How to abuse BSOD for malwares" - oh great, at least we are touching on "development", getting closer. A few thousand hits later, you do get some suggestions, but first always for XP or similar obsolete system. I never really found the answer I think, I call DbgBreakPoint() at the moment, since I want my remote-kernel-debugger to stop and let me inspect. I'll revisit this question before the first non-debug build
Just too much information.
Eventually, I got everything to compile. (albeit with thousands of warnings - they are still there if you want something to do!).
And it did not take long to get SPL up and ticking, all taskqs running and firing when needed. After that, ZFS loads and ticks along. Minor XDR issue where size_t is of different size between Unix and Windows, but I can't work out why that would be.
Which meant I needed a short detour to port over userland, so that I could eventually run zpool command to talk to the kernel. Userland already has a "soft" kernel shim layer, so it is already pretty portable. One of the big changes is that the "file descriptors" - ie the integer file id used by POSIX, is very limited on Windows, and there were quite a few things I could not really do with them. So userland porting included changing the integer file descriptors, to the Windows HANDLE type, replacing open() siblings with CreateFile() equivalent. Trivial.
At this point, ZFS and zpool/zfs command worked, you could do everything (!) but mount the file system. So create, destroy, snapshot, rename, get/set properties and all that. Naturally, ZFS without mounts is not really all that exciting so next up was to handle mount requests to the kernel.
Of course Windows do not have mount requests. Rats.
Looking around at other solutions, in particular Dokan, and btrfs for Windows, the standard seems to create a new "virtual" disk, which you then attach your filesystem to. For ZFS I created new ioctls from userland, for mount and unmount. The way ZFS works, is userland controls what is mounted, where and when. So this code can all stay the same, making future merges easier.
The mounting problem was the second brickwall I came across, where I spent weeks trying to find a way to make it work. First week you try increasingly more and more insane things. The second week I spend asking on stackoverflow or similar places, and by third week and not getting any answers, I give up and properly learn how it works.
But finally, after about 3 months from when I started, I could do the actual porting work - The actual porting! ie changing the Unix vnops to Windows... whatever they are.
So in Windows, they are IRP (IO Request Packet) in form of MaJor and MiNor numbers. For example IRP_MJ_CREATE.
Naive lundman went and counted the Unix VNOPs under OsX, and its roughly some 30-40 of them. Things like vnop_mkdir, vnop_remove and vnop_lookup. Familiar, relaxing.. they refer to single operation, almost like an atomic transaction, tight bit of code to do just that operation, like creating a directory. Clean, nice.
Under Windows, when I counted up the IRP_MJ_ I found there were more than 100 entries! Wow, I thought, they must be even more tight, perhaps several calls to make up a single transaction! Super clean! Hah!
I started with IRP_MJ_CREATE which was surprising. I was looking for a vnop_lookup but I assumed (young past lundman) that IRP_MJ_CREATE was vnop_create. But really the way to think about it is that it creates a handle to an object, which can either exist, or be created.
So then IRP_MJ_CREATE can open existing files and directories, so it is in fact vnop_lookup. Great!
But of course, you can create new files when you call IRP_MJ_CREATE, so it is also vnop_create. Oh
and, IRP_MJ_CREATE can also create new Directories, so add vnop_mkdir to that list. Come on!
There is also DeleteOnClose flag you can pass to IRP_MJ_CREATE, so it needs to call vnop_remove when the handle is closed. Of course you can!
It was about three months later, when I was wondering why I had to keep cleaning up empty directories after running the Windows tester tool ifstest.exe that I discovered that DeleteOnClose can also be set for Directories! So add vnop_rmdir to that list. Surprise!
Updated 2019 - So it seems that IRP_MJ_CREATE can also take a list of EAs to create at the same time as the open/create of the file/dir. Additional 2019 - and apparently, also return stat (as in getattr) struct in the IRP_MJ_CREATE open/create call.
Updated 2023 - IRP_MJ_CREATE can also be called on a non-existent file, with a stream name, like newfile:newstream and it is expected to create the newfile, then create the newstream and return a handle to newstream. A double create event.
The IRP_MJ_CREATE to Unix vnop_lookup has easily become the largest and most complicated of vnop calls.
Can you imagine Unix code like dh = opendir("dir", DeleteOnClose); closedir(dh); to be the equivalent of rmdir("dir");?
Update - turns out you can also pass in an initial Allocation Size to the IRP_MJ_CREATE call for when a file is created/truncated, so we would need to handle this as well, somehow.
So no, the Windows IRPs are not finer grained calls, there seems to be mostly about 10-20 real calls used for everything, and all the rest are weird obscure(ish) calls, usually in specific areas like scsi. So each IRP ends up being a large function, testing all sorts of incoming flags, and branching out depending on the operation. Even simple calls like IRP_MJ_READ is also called for paging files, so has vnop_pagein included.
It was not too surprising to come across TruncateOnClose after that, not sure I see the point of that flag, but I am no longer fazed! Or something...
During the hackathon at Open ZFS summit 2017, I took a look at the zfs send and zfs recv features, to see how complicated it would be to add that support. It was quite a struggle under OsX, as Apple do not let us call many of the kernel functions. Finding a way to do IO on a file descriptor that could be either a file on disk, or, a pipe to a command, was complicated. With Windows I spent quite a bit of time thinking about how to attack this problem in the kernel, how much would I need to change. What was surprising is how easy the kernel part was, I just changed it to take a HANDLE, like the userland port work, and it just.. worked. So I cleaned that patch up, played with the userland options, and eventually found that zfs send -v did not work. "-v" is just an option to tell zfs to print progress every second. The amount the data sent, speed and ETA. Should be trivial?
Led down a dark avenue trying to get async ioctls to work, which means the copyin/copyout code needs to change (different stack, so permission denied) and same for file descriptor (actually, handle). But that didn't fix it, so turns out that an open /dev/zfs can only do one ioctl at a time, so the thread that does the progress printing just needed to open the /dev/zfs again for itself, and it all works. Delete all new async ioctl code. Userland ended up being the hard part, and the kernel code trivial.
Deleting an entry can also be done by calling IRP_SET_INFORMATION with set_file_disposition with Delete set to TRUE. Again, the actual delete is delayed until close IRP_MJ_CLOSE.
Unix vnop_readdir has 2 structs it can use, the legacy and extended struct. Which is a bit annoying, but the ZFS code already handles that case. On Windows, it turns out that there are at least 9! of these structs (so far). For short-name or long-name, or both. Then again, with file IDs etc. To be fair, I've only seen 4 types used in the wild so far. You can also pass in a glob match pattern to it, which is a pain.
With Unix, the vnode has a v_data void * pointer, which is "yours" to do with as you please. Ie, it can point to whatever data you want, and in ZFS it points to a znode. Under Windows, a FileObject actually has 2 FsContext pointers, which I thought was rather generous. But it turns out to be a lie! With directory listings, you are expected to remember the index offset, and search glob pattern "yourself", in the filesystem, which typically what FsContext2 is used for. But also, if you want memory-mapped (vnop_mmap) to work (you do), you are expected to put in a Windows specific struct inside your struct somewhere, set in Fs_Context. So it feels like suddenly the v_data pointer isn't entirely mine as it would be under Unix. But, really the mmap struct doesn't have to be in the FsContext, I could create some other storage for it, like a linked list and search for it, but it is placed there under all examples, and is much easier to handle when it is time to release it.
This was the third brickwall I came across, after implementing IRP_MJ_READ and IRP_MJ_WRITE, I could do simple IO like cat/type of files and view a PNG image of the cat. But what didn't work was notepad.exe. The simplest of all editors! That turns out to be the mmap problem, and since I failed to include the struct above, no mmap worked, so notepad could not read/write data. Wordpad.exe was fine.
Technically, I probably do not need to create vnodes under the Windows port, but I have mirrored XNU's VFS layer, so I can ASSERT on the vnode iocount references and so on, as well as hold on to the mmap struct above. Eventually the Windows vnode layer should be fleshed out a bit more, so it has a max-vnodes setting to cache vnodes, and a thread that calls reclaim when needed etc. Right now, everything is reclaimed on close, which is slow.
So on the whole "mounting a dataset inside another dataset", or as Windows calls it, "named mount" using REPARSE POINTS. First issue I had was that userland created the directory that was to be mounted on, like standard Unix, then checks that it is empty before calling the kernel to mount something on top of it. Think in Unix terms, a directory is a directory. So turning it into a "reparse point" is just something you "add" on later, like chflags or chmod. Turns out that that is not the case. When you create the directory, you create it WITH reparse point set, and it makes.. something different. Not sure how I'll change userland for it yet, maybe leave it as is, but rmdir in kernel before mounting.
Then is the fact that when you create a reparse point directory, it calls ZFS with FSCTL_SET_REPARSE_POINT, and a struct that it expects the filesystem to store. Like that of a symlink I suppose, except for the mountpoint, set on a directory. The manual labour of a mount inside a mount seems to fall on the filesystem entirely. When looking up an entry (vnop_lookup) I need to detect the directory is a reparse point, read in the stored data, and return that data in "Tail.Overlay.AuxiliaryBuffer" with return code STATUS_REPARSE, and the "Reserved" field set to the number of bytes parsed before hitting this reparse point. .... I'm not sure what to think here.. Also, in readdir, if you want the directory icon to show it is a mounted directory (like NTFS does) - you return 0xa000003 in the EASize field. Are we just bolting on things now?
But it amuses me greatly that I can return different target mountpoint information, based on any criteria I see fit. Be it UserID, process name, moon phase. So Doug entering "Games" might get pointed to the HDD, and Stuart is sent to C:\goats. Great prank!
Way back in the start, I received IRP_MN_NOTIFY_CHANGE_DIRECTORY and assumed it was something it sent to ZFS when you change a directory. Didn't quite get the point of it, but returned A-OK, and moved on. It was quite a bit later while wondering why Devstudio issue 100s of them per second, that I decided to check it out proper like. Turns out it is a "block this request, until this directory changes". As a way to detect something new, or deleted, in a directory. And with me replying A-OK to everything, made it scan the directory and ask to be notified again, pretty much indefinitely. Oops.
Gallery
Screen grabs of various milestones:
ZFSin first discovery (20170411)
ZFSin import scan (20170414)
ZFSin first import (20170414)
ZFSin directory listing (20170517)
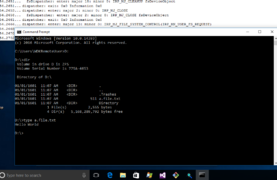
ZFSin reading file (20170517)
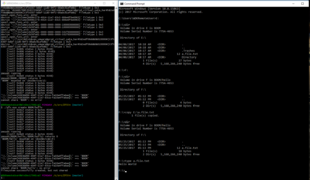
ZFSin zfs create (20170517)
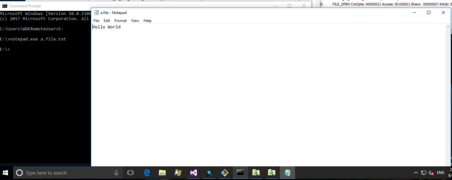
ZFSin notepad (20170614)
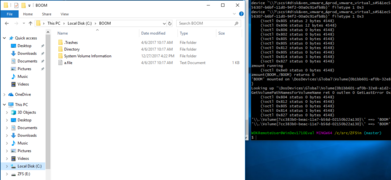
ZFSin named mount (20180112)
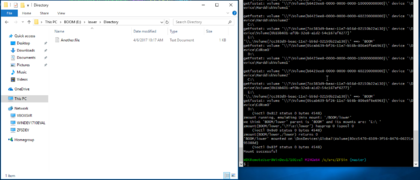
ZFSin mounts in ZFS (20180124)
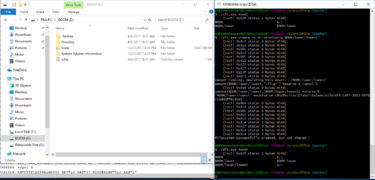
ZFSin mountedtree (20180124)
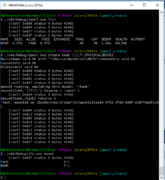
ZFSin first create (20180207)

ZFSin first compile (20180501)
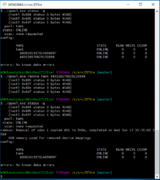
ZFSin device removal (20180501)
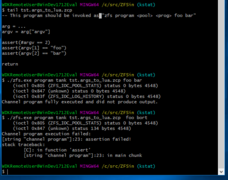
ZFSin channel program (lua script) (20181018)
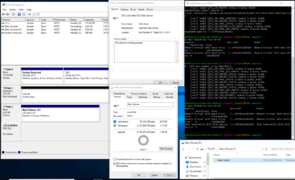
ZFSin ZVOL creation, NTFS format (20190109)
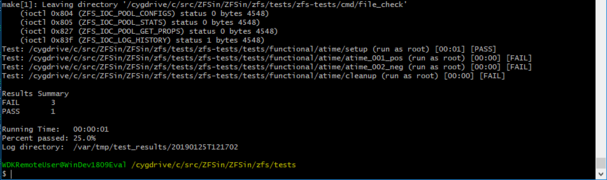
ZFSin first zfstester run (cygwin) (20190125)
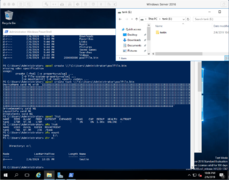
ZFSin Windows Server 2016 (20180207)
















